https://wookjongbackend.tistory.com/19
JDK, JRE, JVM이란 무엇일까?
JDK(Java Development Kit) 저희는 보통 프로젝트를 진행할때, JDK 버전을 직접 선택하게 됩니다. 그러면 이러한 JDK란 무엇일까요?? JDK란 자바 개발 키트(Java Development Kit)의 약자로 Java 언어로 소프트웨어
wookjongbackend.tistory.com
저번 포스트에서 JVM에 대해 간단히 다루어봤는데, 이번 포스팅에서는 JVM 내부 구조 및 메모리 영역과 관련된 개념까지 알아보겠습니다!
JVM의 동작 방식
JVM의 역할은 자바 애플리케이션(. class, 바이트 코드)을 클래스 로더를 통해 읽어 자바 API와 함께 실행하는 것입니다.

위 그림은 자바 프로그램이 실행되면 어떠한 과정을 거치는지 보여주는 그림입니다. 전반적인 과정에 대해 미리 살펴본 후 밑에서 더욱 세세하게 알아보겠습니다!
- JVM 초기화 : JVM이 시작되면, 운영체제로부터 필요한 메모리를 할당받고, 메모리 구조에 따라 영역을 나눕니다. 이 메모리는 JVM이 실행되는 동안 사용되며, 프로그램의 종료와 함께 운영체제에 반환됩니다.
- 컴파일 : 개발자가 작성한 자바 소스코드(.java 파일)는 자바 컴파일러인 javac에 의해 바이트코드(. class 파일)로 컴파일됩니다. 이 바이트코드는 JVM이 이해할 수 있는 언어로, 여러 다른 플랫폼에서 실행될 수 있습니다.
- 클래스 로딩 : 클래스 로더는 동적 로딩을 통해 필요한 클래스들을 로딩 및 링크하여 Runtime Data Area(JVM 메모리 영역)에 올립니다.
- 실행 : Runtime Data Area에 로딩된 바이트코드는 Execution Engine에 의해 해석되고 실행됩니다. Execution Engine은 바이트 코드를 한 줄씩 읽어 가며 기계어로 변환하고 이를 실행합니다. JVM에서 바이트 코드를 직접 해석하는 방식(인터프리터 방식)과 특정 바이트 코드를 네이티브 코드로 변환한 뒤 이를 실행하는 방식(JIT 컴파일러 방식)이 혼용되어 사용됩니다.
- 가비지 컬렉션 : 실행 중에 JVM은 더 이상 필요 없어진 객체들을 자동으로 메모리에서 제거하는 가비지 컬렉션 작업을 수행합니다. 이러한 작업은 프로그램의 효율성과 성능에 크게 영향을 미칩니다.
- 멀티쓰레딩과 동기화 : JVM은 여러 스레드를 동시에 실행할 수 있습니다. 이러한 스레드들 사이에서 공유되는 데이터의 일관성을 유지하기 위해 JVM 동기화 메커니즘을 제공합니다.
이렇게 JVM은 자바 프로그램의 실행과 메모리 관리, 멀티스레딩 및 동기화 등 여러 복잡한 작업을 캡슐화하여 개발자가 비즈니스 로직에만 집중할 수 있게 해 줍니다.
JVM의 구조
JVM이 어떠한 요소로 이루어져 있는지 그림과 함께 살펴보겠습니다

- 클래스 로더(Class Loader)
- 실행 엔진(Execution Engine)
- 인터프리터(Interpreter)
- JIT 컴파일러(Just-In-Time)
- 가비지 컬렉터(Garage Collector)
- 런타임 데이터 영역(Runtime Data Areas)
- 메서드 영역
- 힙 영역
- PC Register
- 스택 영역
- 네이티브 메서드
- JNI - 네이티브 메서드 인터페이스
- 네이티브 메서드 라이브러리
클래스 로더(Class Loader)
앞서, 컴파일된 자바 바이트 코드를 Runtime으로 가져가는 시점에 클래스 로더가 동작한다고 했습니다.
java MainClass이때 Runtime이란 터미널이나 콘솔에서 java 프로그램을 실행시키는 시점을 의미합니다. 이때 실행을 위한 java 명령어(위의 코드가 예시)를 통해 JRE(Java Runtime Environment)가 실행되며, 이후 명령어에 지정된 클래스(ex: MainClass)가 클래스 로더에 의해 로드됩니다. 이 로드 과정은 클래스의 바이트코드를 메모리에 가져오는 작업을 포함합니다.
마지막으로, JVM은 로드된 클래스의 main() 메서드를 호출하여 프로그램을 실행합니다.

자바 컴파일러를 통해. class 확장자를 가지게 된 클래스 파일들은 각 디렉터리에 흩어져 있습니다. 이렇게 흩어져 있는 각각의 클래스 파일을 찾아서 동적 로딩(Dynamic Loading) 방식으로 런타임 영역(Runtime Area), 즉 JVM의 메모리 영역에 탑재해 주는 것이 바로 클래스 로더에 핵심입니다.
이러한 클래스 파일의 로딩 순서는 다음과 같이 구성됩니다. (Loading -> Linking -> Intialization)

- Loading(로딩) : 클래스 파일을 가져와서 JVM의 메모리(Runtime Area)에 로드
- Linking(링킹) : 클래스 파일을 사용하기 위해 검증하는 과정
- Verifying(검증) : 이 단계에서 JVM은 로드된 클래스 파일이 적절한 형식을 갖추며, 안전한지 확인합니다. 예를 들어 JVM 클래스 파일이 가상 머신 규칙에 맞는 바이트 코드를 포함하고 있는지, 올바른 데이터 타입을 사용하는지 등을 확인합니다.
- PreParing(준비) : JVM은 클래스(or 인터페이스)에 필요한 메모리를 할당하고, 해당 메모리를 기본 값으로 초기화합니다. 예를 들어, 클래스 내의 static 필드에 대한 메모리 공간을 할당하고, 각 필드를 해당 타입의 기본값으로 초기화합니다.(실제 코드에 지정된 값으로의 초기화는 Initialzation 단계에서)
- Resolving(분석) : 클래스의 상수 풀 내 모든 씸볼릭 레퍼런스를 다이렉트 레퍼런스로 변경한다.
- Initialization(초기화) : 클래스 변수들을 적절한 값으로 초기화한다(static 필드들을 설정된 값으로 초기화), 이 과정까지 끝나면 JVM에서 클래스 파일을 구동시킬 준비를 마친 것
위에서 심볼릭 레퍼런스란 심볼, 즉 이름에 의해 참조가 이루어지는 것을 의미합니다.(ex : import java.util.*, 이런 것은 컴파일 타임에만 필요하고 런타임엔 필요 X)
예를 들어 클래스 파일 내에 다른 클래스나 메서드 필드를 참조하는 경우, 그 참조는 해당 클래스나 메서드, 필드의 이름으로 이루어지며 이를 씸볼릭 레퍼런스라 합니다.
반면 다이렉트 레퍼런스는 실제 메모리 상의 주소를 바로 참조하는 것을 의미합니다. 이는 JVM이 실제로 객체를 관리하는 방식으로, JVM 내의 특정 메모리 주소를 가리키게 됩니다.
Loading
로딩이 어떠한 방식으로 진행되는지 좀 더 자세히 알기 위해 Class Loader의 계층 구조에 대해 간단히 살펴보겠습니다.

- Bootstrap Class Loader : JVM이 시작될 때 생성되며, 기본적인 Java API(ex: java.lang 패키지의 클래스)와 Object 클래스와 같은 핵심 자바 API를 로드하는 클래스 로더입니다. 이 클래스 로더는 자바가 아닌 네이티브 코드(C/C++ 등으로) 작성되어 있습니다.
- Extension Class Loader : Bootstrap Class Loader에 이어서 동작하는 클래스 로더로, 기본 Java API를 제외한 확장 클래스들을 로드합니다. 예를 들어, 추가적인 자바 표준 라이브러리(JSTL) 같은 것들을 로드합니다
- Application Class Loader : 이 클래스 로더는 우리가 작성한 애플리케이션의 클래스를 classPath에서 찾아 로드합니다.
클래스 로딩 과정은 다음과 같습니다.
- 클래스 로더가 클래스를 로드하라는 요청을 받으면, 첫 번째로 이전에 로드된 클래스인지를 확인합니다. 이를 위해 클래스 로더 캐시를 확인하게 됩니다. 만약 이전에 로드된 클래스라면 캐시에서 해당 클래스를 반환합니다.
- 만약 캐시에 클래스가 없다면, 요청을 상위 클래스 로더에게 전달합니다. 이 과정은 부트 스트랩 로더까지 이어집니다. 이렇게 상위 클래스 로더로부터 차례로 확인하는 것은 클래스 로더의 위임 모델(delegation model)을 따르는 것
- 만약 부트 스트랩 로더까지 가서도 해당 클래스를 찾지 못했다면, 원래 요청을 받았던 클래스 로더가 파일 시스템에서 해당 클래스를 찾게 됩니다. 이렇게 찾아서 로드된 클래스는 캐시에 저장되어, 다음번에 빠르게 접근할 수 있게 됩니다
실행 엔진(Execution Engine)
실행 엔진은 클래스 로더를 통해 Runtime Data Area에 배치된 바이트 코드를 명령어 단위로 읽어서 실행합니다.
자바 바이트 코드(. class)는 기계가 바로 수행할 수 있는 언어라기 보단, 가상 머신이 이해할 수 있는 중간 레벨로 컴파일된 코드입니다.
이러한 코드는 실행 엔진(인터프리터 or JIT Compiler)을 통해 실제 컴퓨터가 이해할 수 있는 기계어로 변환되어 실행됩니다.
자바에서는 인터프리터와 JIT 컴파일러 방식 두 가지 방식을 혼합하여 바이트 코드를 실행합니다.

여기서 인터프리터란 바이트 코드 명령어를 하나씩 읽어서 해석하고 바로 실행하는 것입니다.
JVM 안에서 바이트 코드는 기본적으로 인터프리터 방식으로 동작하지만, 이러한 방식은 중복된 코드에 대해서도 매번 다시 해석해야 하므로 효율성이 떨어집니다.
위와 같은 단점을 극복하기 위해 도입된 것이 JIT 컴파일러(Just-In-Time)입니다.
JIT 컴파일러는 프로그램이 실행되는 동안 어떤 코드가 자주 실행되는지, 즉 어떤 부분이 핫스팟인지 분석합니다. 이렇게 분석을 통해 핫스팟을 식별하면, JIT 컴파일러는 해당 코드를 네이티브 코드로 즉석에서 컴파일합니다. 이렇게 컴파일된 코드는 캐시에 저장되어 빠르게 재사용될 수 있습니다. 따라서 같은 코드가 실행될 경우, JIT 컴파일러는 미리 컴파일하고 캐시에 저장해 둔 네이티브 코드를 사용하여 코드를 더 빠르게 실행할 수 있게 합니다. 이렇게 함으로써 JIT 컴파일러는 인터프리터 방식의 오버헤드를 줄이고 성능을 향상시킵니다.
이러한 실행엔진에는 Heap메모리에서 더는 사용하지 않는 메모리를 자동으로 회수하는 Garbage Collector(GC)가 있는데 이는 다음 포스팅에서 상세히 다루어보겠습니다 :)
런타임 데이터 영역(Runtime Data Area)

런타임 데이터 영역은 JVM의 메모리 영역으로, 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역을 뜻합니다.
런타임 데이터 영역은 위 그림과 같이 Method Area, Heap Area, Stack Area, Pc Register, Native Method Stack으로 나뉩니다.

이때 Method Area, Heap Area 영역은 모든 쓰레드가 공유하는 영역이고, 나머지인 PC Register, Stack, Native Method Stack은 각 쓰레드 마다 생성되는 개별적인 영역입니다.
메서드 영역(Method Area)

메서드 영역은 클래스 로더에 의해 로드된 클래스의 바이트 코드, 필드(ex: 멤버 변수 이름, 데이터 타입, 접근 제어자), 메서드(메서드 이름, 리턴 타입, 함수 매개변수 등등)등에 대한 메타 데이터를 보관하는 공간입니다. 클래스의 정적 변수(static 변수, 클래스 변수)도 포함되어 있습니다. 따라서 모든 쓰레드에서 해당 변수에 접근할 수 있겠죠??
런타임 상수풀(Runtime Constant Pool)은 JVM의 Method Area에 위치한 영역으로, 클래스나 인터페이스에 대한 상수, 메서드와 필드에 대한 참조 등을 저장합니다. 이는 각각의 클래스나 인터페이스에 대한 컴파일 타임의 상수 값들을 포함하며, 그리고 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변환하기 위한 추가 정보를 포함합니다.(Resolving과 다르게 실행 도중에도 계속해서 이루어짐)
이러한 정보들은 클래스나 인터페이스의 코드를 실행할 때 필요하며, 이를 통해 JVM은 메서드를 호출하거나 필드에 접근하는 등의 작업을 수행할 수 있습니다.
힙 영역(Heap Area)

힙 영역은 JVM이 관리하는 프로그램에서 데이터를 저장하기 위해 런타임에 동적으로 할당하는 영역입니다.
여기에는 new 연산자로 생성된 객체, 인스턴스 변수, 배열 등의 참조형 타입이 저장됩니다. 이때 기본형 인스턴스 변수의 경우가 아니라 참조형 인스턴스 변수인 경우 데이터 자체를 저장하는 것이 아니라 참조값을 저장한다는 점 유의합시다!
또한 이 영역은 모든 스레드가 공유하기 때문에 특정 클래스를 로드한 후, 인스턴스를 만들 때 해당 인스턴스는 힙 영역에 생성되며 모든 스레드에서 이를 참조할 수 있습니다.
이렇게 힙 영역에 생성된 객체는 JVM 스택 영역의 변수 또는 다른 객체의 필드를 통해 참조됩니다. 이렇게 참조되는 동안 객체는 생존하지만, 더 이상 참조되지 않으면 GC의 대상이 됩니다.

이러한 힙 영역은 효율적인 메모리 관리를 위해 Young Generation 영역과 Old Generation 영역으로 나뉘며, Young Generation 영역은 또한 Eden 영역과 두 개의 Survivor 영역으로 분리됩니다.
다음 포스팅에서 좀 더 상세히 다루어 볼 것이지만 우선 간단히 살펴보자면 객체가 처음 생성되면 Eden 영역에 위치하게 됩니다.
가비지 컬렉션 이후에도 생존한 객체들은 Surivivor 영역으로 이동하게 됩니다. 이때 Survivor 영역은 두 개가 있으며, 객체가 가비지 컬렉션에서 생존하면 이 두영역을 왔다 갔다 하게 됩니다.
이후 Young Generation에서 계속 생존한 객체는 결국 Old Generation 영역으로 이동하게 됩니다. 이 영역에 위치한 객체는 일반적으로 생명주기가 긴 객체로 간주됩니다.
스택 영역(Stack Area)

스레드가 시작될 때마다 각 스레드는 JVM Stack을 할당받습니다. 이러한 Stack은 스레드에 의해 생성되며, 각 스레드의 수행 과정에서 메
서드 호출과 지역 변수에 대한 정보를 담습니다.
이때 각 메서드 호출은 스택 프레임이라는 하나의 엔트리를 만들고 이를 스택에 push 합니다. 각각의 스택 프레임은 메서드 호출에 대한 정보를 포함하는데, 이에는 지역 변수, 반환값, 메서드에 대한 참조 등이 포함됩니다. 메서드 호출이 완료되면 해당 스택 프레임은 Pop이 되어 제거됩니다. 이러한 스택은 사이즈가 고정되어 있어 런타임 시에 사이즈를 바꿀 수 없으며, 고정된 크기를 넘는 경우 StackOverFlow가 발생하게 됩니다.
단, 데이터 타입에 따라 스택과 힙에 저장되는 방식이 다르다는 점을 유의해야 합니다.
기본형 타입 변수는 스택영역에 직접 값을 가지는데 반해, 참조 타입의 변수는 힙 영역이나 메서드 영역의 객체 주소를 가집니다.

위와 같이 Person p = new Person();과 같이 클래스를 생성할 경우, new에 의해 생성된 클래스는 Heap Area에 저장되고, Stack Area에는 생성된 클래스의 참조인 p만 저장됩니다.
PC(Program Counter) Register
PC 레지스터는 현재 스레드가 수행 중인 JVM 명령어 주소를 저장하는 공간입니다.
JVM은 여러 쓰레드를 동시에 처리할 수 있는 능력을 가지고 있으며. 이러한 다중 쓰레드 환경에서 각 쓰레드는 자신만의 PC 레지스터를 가지고 있습니다. 이는 각 쓰레드가 독립적으로 작업을 수행할 수 있게 해주며, 여러 쓰레드가 동시에 실행될 때 서로 간섭하지 않도록 하는 역할을 합니다.
어떻게 독립적으로 작업을 수행할 수 있는지 하나의 예시와 함께 이해해보겠습니다!
예를 들어, 한 쓰레드가 현재 실행 중인 명령어를 중단하고 다른 쓰레드가 수행되어야 할 경우(Context Switching), 첫번째 쓰레드의 PC 레지스터는 그 쓰레드가 다시 실행될 때 어디서부터 시작해야 하는지를 가리키는 주소를 유지합니다. 이렇게 함으로써 각 쓰레드는 자신의 작업을 독립적으로 수행하고, 다른 쓰레드의 작업에 영향을 주지 않는 것입니다.
이러한 PC Register의 값은 쓰레드가 수행하는 메서드의 유형에 따라 달라집니다. 자바 메서드를 수행하는 경우, PC 레지스터는 현재 수행 중인 명령어의 주소를 가지게 되는 반면 쓰레드가 네이티브 메서드(ex: C언어로 작성된 메서드, JNI를 통해 java코드와 연결 가능)를 실행하는 경우 PC레지스터는 정의되지 않은 상태가 됩니다. 이후 실행이 완료되면 PC 레지스터는 다음 명령의 주소로 업데이트 됩니다.
네이티브 메서드 스택 (Native Method Stack)
네이티브 메서드 스택은 자바 코드가 아닌 기계어로 작성된 프로그램 즉 네이티브 메서드를 실행시키는 영역입니다.
네이티브 메서드는 주로 C, C++, 어셀블리 등의 언어로 작성된 코드를 가리키며, JVM의 Just-In-Time 컴파일러에 의해 변환된 네이티브 코드 역시 여기에서 실행됩니다.

자바에서 메서드를 실행하는 일반적인 경우에는, 해당 메서드의 실행 상태는 JVM 스택에 저장됩니다. 그러나 해당 메서드가 네이티브 메서드를 호출하면, 그 네이티브 메서드의 실행 상태는 네이티브 메서드 스택에 저장됩니다. 네이티브 메서드의 수행이 끝나면 제어권이 다시 JVM 스택으로 돌아와 이전의 자바 메서드 실행을 계속합니다. 이를 통해, 자바 프로그램은 네이티브 코드로 작성된 함수를 직접 호출하고 그 결과를 받아올 수 있습니다.
그러나 주의할 점은, 네이티브 메서드 스택이 네이티브 메서드의 기계어 코드를 직접 저장하는 공간은 아니라는 것입니다. 네이티브 메서드 스택에 저장되는 것은 네이티브 메서드의 실행 상태 정보이며, 실제 네이티브 메서드의 기계어 코드는 보통 운영체제의 메모리 공간에 로드되어 실행됩니다. 네이티브 메서드 스택은 네이티브 메서드의 호출 정보, 지역 변수 등의 실행 컨텍스트를 추적하고 저장하는 역할을 합니다
JNI(Java Native Interface), Native Method Library
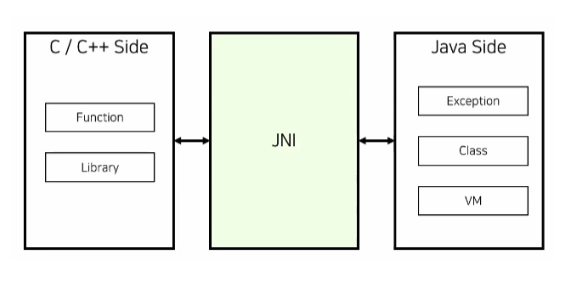
JNI는 자바가 네이티브 애플리케이션과 상호작용하도록 만들어진 프로그램입니다. JNI는 자바 코드에서 네이티브 메서드를 호출하거나 네이티브 코드에서 자바 객체를 사용한 등의 작업을 가능하게 합니다. 즉 JNI는 JVM 내부에서 실행되는 자바코드와 운영체제가 제공하는 API나 다른 소프트웨어 라이브러리와 같은 네이티브 코드 간의 다리 역할을 합니다.
Native Method Library는 일반적으로 C또는 C++로 작성된 라이브러리를 의미합니다. 만일 헤더가 필요하다면 JNI는 이 라이브러리를 로딩해 실행합니다
참고
지금까지 JVM과 이와 관련된 요소들에 대해 다루어봤습니다!
긴글 읽어주셔서 감사하고 잘못된 내용이 있다면 피드백 부탁드리겠습니다 :)
https://inpa.tistory.com/entry/JAVA-☕-JVM-내부-구조-메모리-영역-심화편#
https://tecoble.techcourse.co.kr/post/2021-07-15-jvm-classloader/
https://velog.io/@ariul-dev/차근차근-알아보는-Java-프로그램-실행-과정
https://www.youtube.com/watch?v=UzaGOXKVhwU
https://haloworld.tistory.com/139
'JAVA' 카테고리의 다른 글
| Garbage Collection 한 눈에 알아보기! (0) | 2023.06.01 |
|---|---|
| JDK, JRE, JVM이란 무엇일까? (0) | 2023.05.30 |
| Collection Framework 완전 정복 6탄(마지막편) - Map인터페이스(HashMap, LinkedHashMap,HashTable, TreeMap) (2) | 2023.05.29 |
| Collection Framework 완전 정복 5탄 - Set인터페이스 (HashSet, LinkedHashSet) (0) | 2023.05.28 |
| Hash, HashFunction, HashCollision 완벽 정복하기! (0) | 2023.05.26 |



