Hash, HashFunction 이란?
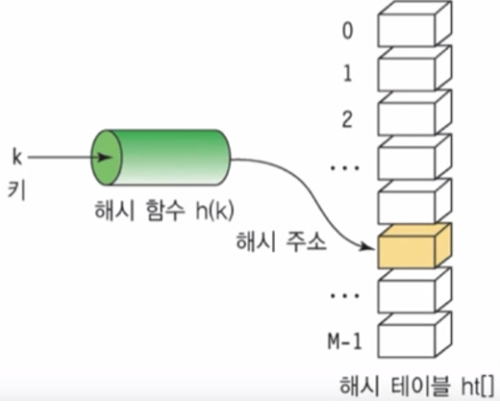
Hash란 일반적으로 key가 Hash Function을 통과하여 암호화되어 나온 결과물을 의미합니다.
그리고 Hash Function은 임의의 길이의 입력값을 고정 길이의 암호화된 출력으로 변환해 주는 함수를 뜻합니다.
이러한 해시 함수는 크게 세가지의 특징을 가집니다.
- 어떤 입력 값에도 항상 고정된 길이의 해시값을 출력한다.
- 입력 값의 아주 일부만 변경되어도 전혀 다른 결과 값을 출력한다
- 출력된 결과값을 통해 입력값을 유추할 수 없다.
우선 첫번째 특성을 살펴보면, 입력값이 짧든 길든 항상 동일한 길이의 해시값이 출력된다는 것을 알 수 있습니다.
이러한 해시에는 크게 MD 알고리즘, SHA 알고리즘이 있는데 SHA알고리즘을 통해 특징들을 이해해 보겠습니다.

위 그림을 살펴보았을 때, 인풋 값의 길이가 다르지만 아웃풋으로 나오는 해시의 길이는 고정되어 있음을 확인할 수 있습니다.

또한 숫자하나 차이인데도 해시 값이 패턴?을 가지지 않고, 전혀 다른 형식으로 출력되는 것을 확인할 수 있습니다.
자바 코드와 함께 이해해보기
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, String> map = new HashMap<>();
// "ARGOS"라는 키에 "Shop"라는 값을 저장
map.put("ARGOS", "Shop");
// "ARGOS"라는 키에 대응하는 값을 검색
String value = map.get("ARGOS");
// 결과 출력
System.out.println("The value for key 'ARGOS' is: " + value);
}
}위 코드에서는 ARGOS라는 키와 SHOP이라는 값을 HashMap에 저장하고 잇습니다. 이때 HashMap은 내부적으로 ARGOS라는 키의 해시값을 계산하여 이 값을 인덱스로 사용합니다.
따라서 map.get("ARGOS")를 호출할 때, HashMap은 먼저 ARGOS라는 해시값을 계산하고, 이 해시값을 인덱스로 사용하여 저장된 값을 검색합니다. 그래서 ARGOS에 대응하는 SHOP이라는 값을 얻을 수 있습니다.
위와 같이 해시맵은 해시 함수를 사용하여 키를 저장소의 인덱스로 변환하여 키-값 쌍을 효율적으로 저장하고 검색할 수 있게 합니다.
이러한 해시맵의 가장 기본적은 구조는 배열이나(해시 함수로 얻은 인덱스에 key-value 저장), 체이닝을 사용할 때는 연결리스트를 사용합니다.
해시 충돌(Hash Collision)이란??
이렇게 Hash Function 사용 시에는 주의해야 할 점이 있습니다. 해시 함수는 입력 값의 길이가 어떻든 고정된 길이의 값을 출력하기 때문에 입력값이 다르더라도 같은 결괏값이 나오는 경우가 있습니다. 이를 해시 충돌이라고 하며, 해시 충돌이 적은 함수가 좋은 해시 함수라고 부릅니다. 이때 적은 것뿐 아니라 해시 충돌이 균등하게 발생하도록 하는 것 또한 중요합니다. 모든 키가 같은 해시값이 나오게 되면 데이터 저장 시 비효율성이 커지고 보안이 취약해져서 좋지 않겠죠??
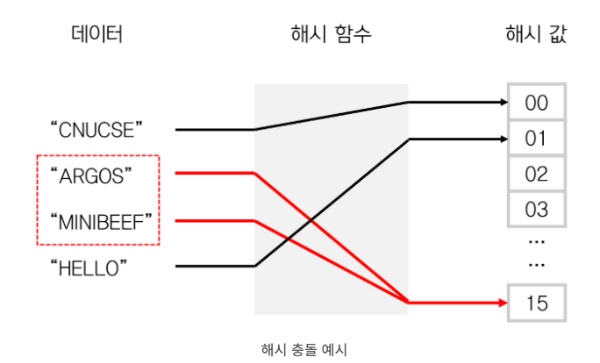
위 그림을 보면 두 다른 문자열이 key값으로 사용되어 해시 함수를 통과하였지만 둘 다 15라는 동일한 값이 출력되었습니다. 이러한 상황을 해시 충돌이라고 하는데 좀 더 상세히 알아보기 위해서는 먼저 적재율(load factor)의 개념에 대해 명확히 해야 합니다.
적재율이란 해시 테이블의 크기에 대한 키의 개수의 비율을 뜻합니다. 즉 키의 개수가 K, 해시 테이블의 크기가 N이라면 적재율은 K/N이 됩니다.
만약 이러한 해시 충돌이 없다면, 즉 각각의 키가 각각의 유일한 해시값을 가지고 있다면, 키를 통해 바로 값을 찾을 수 있으므로 탐색, 삽입, 삭제 연산이 모두 상수 시간 O(1)이 소요됩니다.
하지만 해시 충돌이 발생한 경우에는, 즉 두 개 이상의 다른 키들이 같은 해시 값을 갖는다면 어떨까요???
이 경우 해시 테이블은 두개 이상의 키 값을 같은 인덱스에 저장해야 하는 상황에 놓입니다.
이때 대표적으로 사용하는 해결방법이 Chaining과 Open Addressing입니다.
나중에 좀 더 자세히 이에 다루어 볼 것인데 간단히 설명드리자면 체이닝이란 같은 해시 값을 가지는 키들을 연결리스트로 묶어 같은 인덱스에 저장하는 방법이고, 반면 오픈 어드레싱은 충돌이 발생했을 때 다른 인덱스를 찾아가며 빈 공간을 찾아 저장하는 방식입니다.
체이닝으로 해시 충돌을 해결하게 되면, 원하는 키 값을 찾기 위해서는 그 인덱스에 있는 모든 키 값을 확인해야 합니다.
이때 탐색과 삭제 시간 복잡도는 O(k)가 되며, 여기서 K는 해당 인덱스에 저장되어 있는 키의 개수를 의미합니다.
오픈 어드레싱을 사용해 충돌을 해결한 경우, 특정 키 값을 찾기 위해서는 해당 키의 해시 값을 얻은 후, 해당 해시값부터 탐색(프로빙)을 시작합니다. 이후 오픈 어드레싱 방식에 따라 다른 위치로 이동하며 원하는 키 값을 가진 항목을 찾을 때까지 탐색을 진행합니다.
여기서 프로빙이란, 충돌이 발생했을 때 다른 위치를 찾아나가는 과정입니다(일반적으로, 선형, 이차, 더블 해싱)
이러한 오픈 어드레싱의 탐색 및 삭제 연산의 평균 시간 복잡도는 로드팩터(a)에 따라 달라집니다.
로드 팩터가 증가하면 즉, 해시 테이블이 가득 차게 될 확률이 증가하므로, 충돌을 해결하기 위한 프로빙 횟수도 증가하게 됩니다. 따라서 로드 팩터가 증가할수록 시간 복잡도는 증가하며, 이는 O(1/(1-a))에 비례합니다.
HashMap은 키 집합인 정의역과, 값 집합인 공역의 대응하여 해시 함수를 이용하기에 해시 충돌이 하나도 일어나지 않는 해시 함수를 만드는 것은 비둘기집 원리에 의해 불가능합니다(정의역의 개수가 더 많은 경우 해당)
따라서 해시 충돌에 대한 안전하다는 해시 함수는 충돌이 거의 일어나지 않는다라는 의미 합니다.
비둘기집 원리
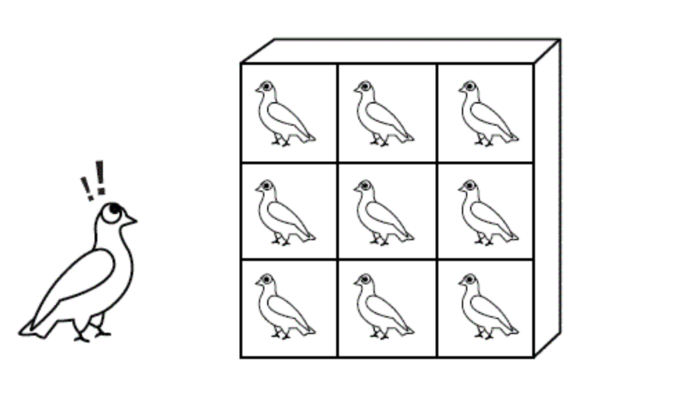
비둘기집 원리란 수학에서 자주 사용되는 원리로, 단순히 표현함 n개의 비둘기집에 n+1 마리의 비둘기를 집어넣으려고 하면, 반드시 어떤 한 비둘기집에는 반드시 2마리 이상의 비둘기가 들어가게 된다는 원리를 말합니다.
즉, 원소의 개수가 더 많은 집합을 원소의 개수가 더 적은 집합에 매핑하려고 할 때, 반드시 한 개 이상의 원소가 같은 위치에 매핑되는 현상을 의미합니다.
해시맵은 키를 해시함수를 통해 특정 인덱스로 매핑하는데, 가능한 모든 키의 집합이 가능한 모든 해시 값의 집합보다 크거나 같은 경우에는 반드시 해시 충돌이 발생한다는 것입니다.
그렇다면 가능한 모든 키의 집합이 가능한 모든 해시 값의 집합보다 작다면 해시 충돌은 무조건 발생하지 않을까요???
발생하지 않을 가능성이 높아지는 것이지 결론적으로는 아니라고 볼 수 있습니다. 예를 들어 해시 함수가 일부 해시 값을 과도하게 선호하는 경우엔 해시 충돌이 발생할 수 있겠죠??
해시 충돌 완화 방법
해시 충돌을 완화하는 방법에는 크게 Open Addressing과 Separating Chaining 방법이 있습니다.
- 개방 주소법(Open Addressing) : 해시 테이블 크기는 고정하면서 저장할 위치를 찾는다.
- 분리 연결법(separate Chaining) : 해시 테이블의 크기를 유연하게 만든다.
각각의 방법에 대해 한번 알아보겠습니다.
개방 주소법(open-address)
open-address는 한 버킷 당 들어갈 수 있는 엔트리는 하나이지만, 해시 함수로 얻은 주소가 아닌, 다른 주소에 데이터를 저장할 수 있도록 허용하는 방법입니다.
충돌이 발생할 경우 프로빙을 바탕으로 다음 slot을 찾아 나갑니다.
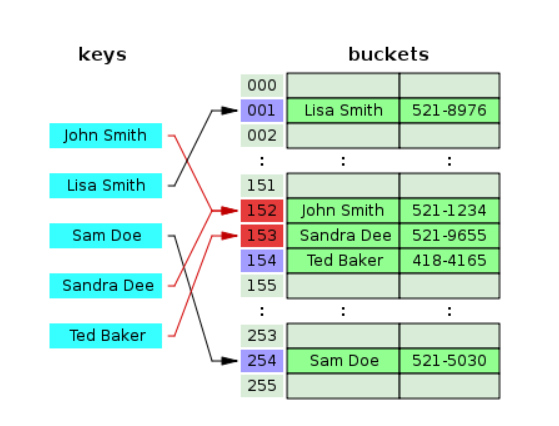
그림을 보면, John Smith와 Sandra Dee를 키로 넣었을 때 해시함수에 의해 같은 값은 152가 리턴된다고 해봅시다. 그런데 John은 152번에 저장되었지만, Sandara Dee는 152에 덮어 씌워지지 않고, 153번에 저장되어 있습니다. 다음 153번을 리턴 받은 Ted Baker는 이미 Sandra Dee가 저장되어 있기에 다음 빈 버킷은 154에 저장되었습니다.
위 예시는 한 칸씩 찾는 방법으로 예를 들었지만 비어있는 칸을 찾아가기 위해서는 아래와 같은 다양한 방법들이 존재합니다.
선형 탐사법(linear Probing)
말 그대로 선형으로 순차적 검색을 하는 법입니다. 해시 함수로 나온 해시 값(index)에 이미 다른 값이 저장되어 있다면, 해당 해시값에서 고정된 폭만큼 옮겨 다음 빈칸을 찾는 방법입니다.
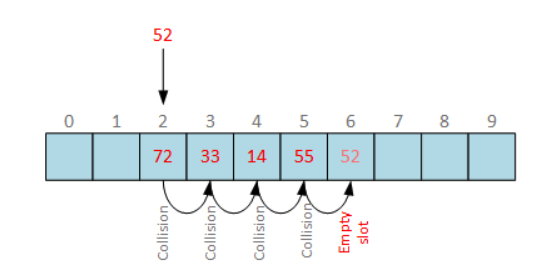
위 경우 52인 key값을 해싱하였을 때 2가 리턴되어, 이를 바탕으로 값을 저장하기에 접근하여으나 이미 충돌이 났음을 알 수 있습니다. 따라서 임의의 고정된 크기인 한 칸씩 옮겨서 빈칸을 찾게 되고, 최종적으로 6에 저장되는 것을 확인할 수 있습니다.
이러한 로직의 구현은 매우 간단하지만, Primary Clustering이라는 문제가 발생할 수 있습니다. 이는 테이블의 연속된 공간에 데이터가 몰리는 현상을 의미합니다. 예를 들어 위의 상황에서 계속해서 해싱 값이 2로 나온다면 2부터 계속 값이 쌓이게 될 것이고, 갈수록 순차적으로 방문해야 할 값들이 많기에 탐색 효율이 떨어질 수 있다는 문제점이 있습니다.
이러한 선형 탐사법은 해시 충돌이 해시 값 전체에 균등하게 발생할 때 유용한 방법입니다.
제곱 탐사법
제곱 탐사법은 위의 선형 탐사법과 동일한데, 탐사 폭이 고정된 값이 아니라 제곱으로 늘어나는 점에서 차이가 있습니다.
즉, 빈 버킷의 slot을 찾기 위해 고정된 값이 아닌 2^1, 2^2, 2^3.... 의 방식으로 이동해서 빈칸을 찾습니다.
제곱 탐사법을 이용한 경우 데이터 밀집도가 선형 탐사법보다 낮기 때문에 다른 해시값까지 영향을 받아서 연쇄적으로 충돌이 발생할 가능성이 적습니다. 하지만 선형 탐사법보다는 캐시의 성능이 떨어져 속도의 문제가 발생합니다. 즉 배열의 크기가 커짐에 따라 L1, L2 Cache Hit ratio가 낮아지기 때문입니다.
제곱 탐사법을 사용하면 해시 테이블의 데이터가 메모리 공간에 균등하게 분포되지 않고, 일부 공간에 집중될 수 있습니다(특정 제곱 값들에만 값이 집중됨). 이렇게 되면, 자주 접근하는 데이터가 캐시에 존재하지 않을 확률이 높아집니다. 즉 대부분의 데이터 접근이 메인 메모리를 통해 이루어질 수 있다는 것이겠죠?
또한 Primary Clustering을 어느 정도 완화할 수 있지만 서로 다른 키들이 동일한 순서의 탐사 경로를 가질 수 있어 발생하는 Secondary Clustering이라는 새로운 문제가 발생할 수 있습니다.
이중 해싱
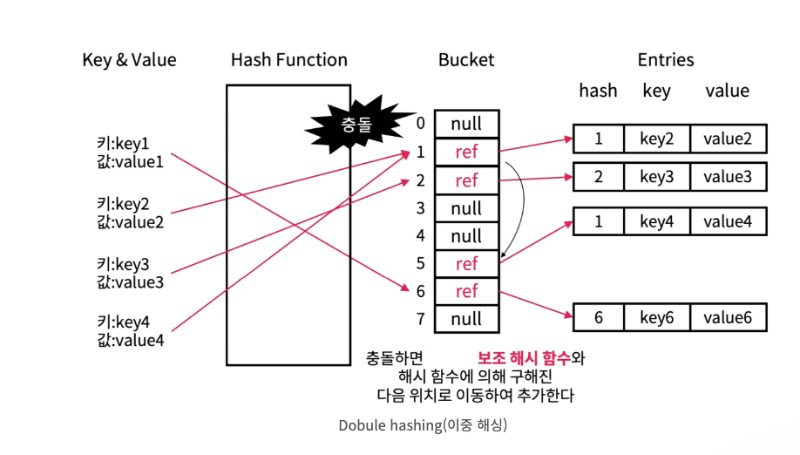
이중해싱법(재해싱)은 항목을 저장할 다음 위치를 결정할 때, 원래 해시 함수와 다른 별개의 해시 함수를 사용하는 방법입니다. 이 방법은 항목들을 이전 방법들보다 해시 테이블에 보다 균일하게 분포시킬 수 있어 효과적입니다.
하나는 처음 key를 저장할 index를 찾기 위한 것이고, 나머지 하나는 충돌 발생 시 저장할 index를 찾기 위한 것이며, 충돌 발생 시 저장할 index를 찾기 위한 해시 함수는 첫 번째 해시 함수와 달라야 합니다.
이러한 이중 해싱 방법은 로드 팩터가 높거나, 데이터의 분포가 매우 불균형할 때 적합합니다.
그러나 이중 해싱에서는 두 번째 해시 함수를 사용하여 새로운 해시 값을 생성하고 이를 기반으로 새로운 탐색 경로를 결정합니다. 이 과정에서 빈 슬롯을 찾기 위해 메모리 내의 여러 위치를 불규칙하게 접근하게 됩니다. 즉 이중 해싱은 해시 테이블의 여러 위치를 불규칙하게 접근하므로 캐시 최적화를 방해하게 됩니다.
충돌의 발생 가능성은 가장 적으나, 캐시의 성능이 선형이나 제곱 탐색법과 비교했을 때 가장 좋지 않고, 추가적인 해시 연산이 들어가기에 가장 많은 연산양을 요구합니다.
정리
탐색 방식에 따라 개방 주소법의 해시의 성능이 달라지지만, 가장 큰 영향을 미치는 요소는 load factor입니다.
(테이블이 꽉 차면 probing이 실패하여 끝나버리기도 함)
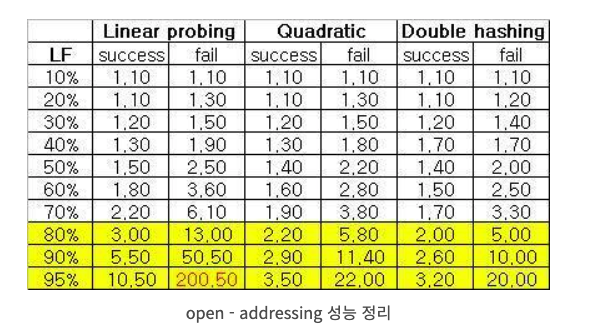
위 그림을 보면 어떤 해시 함수를 쓰더라도 일반적으로 Load Factor가 80 이내까지만 좋은 성능을 보여주는 것을 볼 수 있습니다. 특히 Linear probing 방식이 Load factor가 높을수록 급격한 성능저하를 보입니다.
임계점을 넘은 경우 성능은 이중 > 제곱 > 선형 순서로 성능을 보입니다.
분리 연결법(separate Chaining) or 개방 해싱(Open Hashing)
분리 연결법은 개방 주소법과 달리 한 버킷당 들어갈 수 있는 엔트리 수에 제한을 두지 않는 방식입니다.
이때 버킷은 링크드 리스트나 트리를 사용합니다.
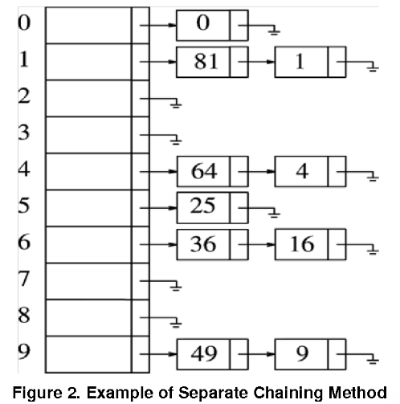
위 그림을 보면 동일한 값들은 리스트로 연결되어 저장됩니다. 따라서 해시 충돌이 일어나더라도 리스트로 노드가 연결되기에, index가 변하지 않고 데이터 개수에 제약이 적습니다.
하지만 개방 주소법에 비해 추가적인 메모리 공간이 필요하며(다음 노드를 가리키는 포인터에 대한 공간), Load Factor에 따라 선형적으로 성능이 저하됩니다. 즉 로드 팩터가 증가하면 각 해시 버킷에 저장된 키-값 쌍의 수도 증가하므로, 특정 키를 찾는데 필요한 시간이 증가합니다.
따라서 데이터가 적은 경우에는 개방 주소법이 평균적으로 더 빠릅니다. 왜냐하면 개방 주소법은 충돌이 발생하더라도 추가적인 메모리 공간 없이 원래의 해시 테이블 내에서 충돌을 해결하기 때문입니다.
위의 2가지 방법 이외에도 해시 테이블의 적재율이 높아진 경우에는 크기가 더 큰 새로운 테이블을 만들어서 기존 데이터를 옮겨서 사용하는 방법이 있습니다. 또한 분리 연결법을 사용했을 경우엔 재해싱을 통해서 너무 길어진 리스트의 길이를 나누어서 다시 저장할 수도 있습니다.
참고
지금까지 Hash, Hash Function, Hash Collision에 대해 다루어봤습니다!! 이해하시는데 도움이 되었으면 좋겠습니다
틀린 내용에 대한 지적은 언제나 환영합니다 ^^
자바의 정석
https://dkswnkk.tistory.com/679
https://velog.io/@mooh2 jj/Hash% EC% 9D%98-%EA% B0% 9C% EB%85%90-%EB% B0%8F-%EC%84% A4% EB% AA%85
'JAVA' 카테고리의 다른 글
| Collection Framework 완전 정복 6탄(마지막편) - Map인터페이스(HashMap, LinkedHashMap,HashTable, TreeMap) (2) | 2023.05.29 |
|---|---|
| Collection Framework 완전 정복 5탄 - Set인터페이스 (HashSet, LinkedHashSet) (0) | 2023.05.28 |
| Collection Framework 정복 4탄 - Heap, PriorityQueue, Deque (0) | 2023.05.26 |
| Collection Framework 정복 3탄 - LinkedList (0) | 2023.05.23 |
| Collection Framework 정복 2탄 - List 인터페이스와 ArrayList (0) | 2023.05.22 |



