현재 포스팅은 영한님의 스프링의 핵심원리 - 기본편을 바탕으로 작성한 포스팅입니다 :)
스프링 핵심 원리 - 기본편 - 인프런 | 강의
스프링 입문자가 예제를 만들어가면서 스프링의 핵심 원리를 이해하고, 스프링 기본기를 확실히 다질 수 있습니다., 스프링 핵심 원리를 이해하고, 성장하는 백엔드 개발자가 되어보세요! 📢
www.inflearn.com
IOC(Inversion Of Control)
IOC란 프로그램의 제어 흐름을 (개발자 or 코드 내에서) 직접 제어하는 것이 아니라 외부에서 관리하는 것을 의미합니다.(프레임워크 같은 느낌)
스프링 애플리케이션에서는 빈의 생성과 의존관계 설정등의 작업을 애플리케이션의 코드 대신 스프링 컨테이너가 담당하고 있습니다. 이를 스프링 컨테이너가 코드 대신 오브젝트에 대한 제어권을 가지고 있다해서 IOC라고 부릅니다.
따라서 스프링 컨테이너를 IOC 컨테이너라고도 부릅니다.
IOC 컨테이너
스프링에서는 IOC를 담당하는 컨테이너를 빈 팩토리, DI 컨테이너, 애플리케이션 컨텍스트라고 부릅니다.
애플리케이션 런타임 시점에 외부에서 실제 구현 객체를 생성하고 클라이언트에 전달해서, 클라이언트와 서버의 실제 의존관계가 연결되는 DI 관점에서 보면, 컨테이너를 빈 팩토리 또는 DI 컨테이너라고 부릅니다.
그러나 스프링 컨테이너는 단순한 DI보다 더 많을 일을 하는데, DI를 위한 빈 팩토리에서 여러가지 기능을 추가한 것을 애플리케이션 컨텍스트라고 합니다.
즉 애플리케이션 컨텍스트는 그 자체로 IOC와 DI 그 이상의 기능을 가졌다고 볼 수 있습니다.

ApplicationContext applicationContext = new AnnotationConfigApplicationContext(App.Config.class);우선 위 코드를 바탕으로 Application Context인 스프링 컨테이너를 생성했다고 가정해보겠습니다.
생성 시 인자로 AppConfig.class를 지정하였는데, 여기엔 여러 빈들의 설정 정보가 담겨 있습니다.

이때 컨테이너는 AppConfig.class의 클래스 정보를 사용해서 스프링 빈을 등록합니다. 이때 빈 이름은 기본적으로 메서드 이름을 사용합니다. @Bean(name = ~~~) 옵션을 사용해서 이름을 직접 부여할 수도 있습니다.
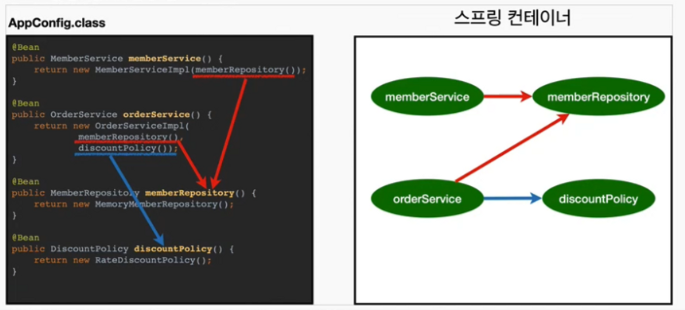
이후 스프링 컨테이너는 설정 정보를 참고하여 의존관계를 주입(DI)합니다.
BeanFactory와 ApplicationContext

BeanFactory는 스프링 컨테이너의 최상위 인터페이스로 스프링 빈을 관리하고 조회하는 역할을 담당하고 있습니다.
ApplicationContext는 BeanFactory의 기능을 모두 상속받아 제공할 뿐 아니라, 메세지소스를 활용한 국제화 기능, 환경 변수, 애플리케이션 이벤트, 편리한 리소스 조회 등의 추가 부가 기능을 제공합니다.
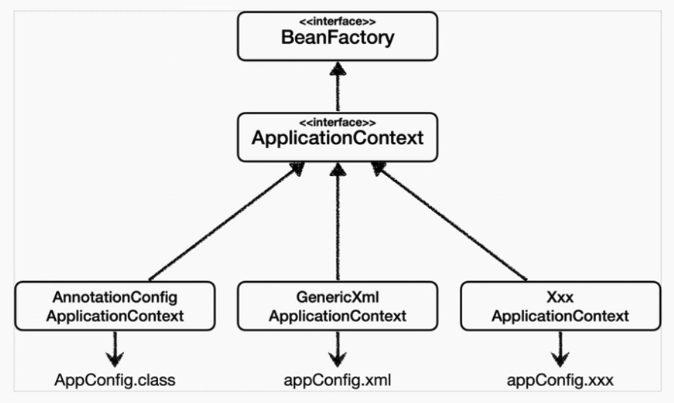
스프링 컨테이너는 다양한 형식(ex: 자바 코드, XML, Groovy)의 설정 정보를 받아드릴 수 있게 유연하게 설계되어있습니다.
그렇다면 스프링은 어떻게 이런 다양한 설정 형식을 지원하는 것일까요??? 이 중심에는 BeanDefinition이라는 인터페이스가 있습니다.

BeanDefinition은 BeanFactoryPostProcessor가 읽을 수 있는 형태로 Bean 설정 메타데이터를 정의하는 인터페이스입니다.
위를 보면 애플리케이션 구동 시 XML을 읽어서 BeanDefinition을 만들 수 있을 뿐 아니라, 자바 코드를 읽어서 BeanDefinition을 만들 수도 있습니다. 따라서 스프링 컨테이너는 설정 정보가 무엇으로 작성되었는지 상관없이 오직 BeanDefinition만 알게 되면 알아서 작업을 진행할 수 있습니다.
싱글톤 패턴과 스프링 컨테이너

원래 스프링이 적용되어있지 않는 순수한 DI 컨테이너의 경우, 요청이 올때마다 객체를 새로 생성하였습니다.
즉 고객 트래픽이 초당 100이 나오면 초당 최소 100개의 객체가 생성되고 소멸되는 것이죠(메모리 낭비)
이를 해결하려면 해당 객체가 딱 1개만 생성되고, 공유하도록 설계하면 됩니다(싱글톤 적용).
싱글톤 패턴이란 클래스의 인스턴스가 딱 1개만 생성되는 것을 보장하는 디자인 패턴입니다. 이는 객체 인스턴스를 2개 이상 생성하지 못하도록 막기 위해 private 생성자를 사용해서 외부에서 임의로 new 키워드를 사용하지 못하도록 막습니다.
public class SingletonService {
// static 영역에 객체를 딱 1개만 생성해둠
private static final SingletonService instance = new SingletonService();
// public으로 열어서 객체 인스턴스가 필요하면, 이 static 메서드를 통해서만 조회하도록 허용
public static SingletonService getInstance(){
return instance;
}
// 생성자를 private으로 선언해서 외부에서 new 키워드를 사용한 객체 생성을 못하게 막음
private SingletonService(){
}
public void logic(){
System.out.println("싱글톤 객체 로직 호출");
}
}딱 1개의 객체 인스턴스만 존재해야 하므로, 생성자를 private으로 막아서 혹시라도 외부에서 new 키워드로 객체 인스턴스가 생성되는것을 막게됩니다.
이러한 싱글톤 패턴을 적용하면 고객의 요청이 올때마다 객체를 생성하는 것이 아니라, 이미 만들어진 객체를 공유해서 효율적으로 사용할 수 있습니다. 하지만 이러한 싱글톤 패턴은 여러 문제점을 가집니다.
- 의존 관계상 클라이언트가 구체 클래스에 의존하게 됩니다(DIP 위반)
- 클라이언트가 구체 클래스에 의존해서 OCP를 위반할 가능성이 높습니다.
- 테스트하기 어렵습니다
결론적으로 싱글톤 패턴은 유연성이 떨어지는 패턴이라 볼 수 있습니다.
스프링 컨테이너는 이러한 싱글톤 패턴을 적용하지 않아도, 객체 인스턴스를 싱글톤으로 관리합니다.
이때 싱글톤 원리가 적용되면, 여러 클라이언트가 하나의 같은 객체 인스턴스를 공유하기 때문에 싱글톤 객체는 상태를 유지하게끔(Restful)하게 설계하면 안됩니다. 즉 무상태(stateless)로 설계해야 합니다.
무상태로 설계하기 위해서는 특정 클라이언트에 의존적인 필드나, 특정 클라이언트가 값을 변경할 수 있는 필드가 존재하면 안됩니다.
public class StatefulService {
private int price; // 상태를 유지하는 필드
public void order(String name, int price){
System.out.println("name = " + name + " price = " + price);
this.price = price; // 여기가 문제;
}
public int getPrice(){
return price;
}
}예를들어 price와 같이 상태를 유지하는 필드가 존재한다고 가정해보겠습니다!
@Test
void statefulServiceSingleton(){
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(TestConfig.class);
StatefulService statefulService1= ac.getBean(StatefulService.class);
StatefulService statefulService2= ac.getBean(StatefulService.class);
// ThreadA : A사용자가 10000원을 주문
statefulService1.order("userA", 10000);
// ThreadB : B사용자가 20000원을 주문
statefulService2.order("userB", 20000);
//ThreadA : 사용자 A 주문 금액 조회
int price = statefulService1.getPrice();
// 위 코드의 의도는 만원이 조회되기를 바람, 하지만 그 사이에 B가 중간에 오더를 해서
// 20000원으로 값이 바뀜
Assertions.assertThat(statefulService1.getPrice()).isEqualTo(20000);
}위 경우 사용자가 가격을 조회할때 10000원이 나오는 것이 아니라 20000원이 조회됩니다. 왜냐하면 price라는 상태를 유지하는 필드를 동기화 없이 사용하였기 때문입니다.
즉 핵심은 스프링 빈은 항상 무상태로 설계하자는 것입니다 :)
DI(Dependency Injection : 의존관계 주입)
서로 의존관계라는 것이 무엇일까요??
굉장히 추상적인 표현으로 볼 수 있지만, 쉽게 이해해보자면 A가 B를 의존한다는것은 의존 대상인 B가 변하면 그것이 A에 영향을 미친다는 것입니다.
class BurgerChef {
private HamBurgerRecipe hamBurgerRecipe;
public BurgerChef() {
hamBurgerRecipe = new HamBurgerRecipe();
}
}만약 현재 객체인 쉐프가 다른 레시피를 사용하여 햄버거를 만들려 한다면 기존의 생성자 부분의 코드를 burgerRecipe = new CheeseBurgerRecipe()와 같이 수정해야 합니다. 즉 클라이언트쪽 코드를 건들여야 한다는 것이죠
이때 만약 DI를 통해 어떤 햄버거 레시피를 만들지를 버거 가게 사장님이 정하는 사장이라고 가정해봅시다.즉 BurgerChef가 의존하고 있는 BurgerRecipe를 외부(사장님)에서 결정하고 주입하는 것이죠
class BurgerChef {
private BurgerRecipe burgerRecipe;
public BurgerChef(BurgerRecipe bugerRecipe) {
this.burgerRecipe = bugerRecipe;
}
}
//의존관계를 외부에서 주입 -> DI
new BurgerChef(new HamBurgerRecipe());
new BurgerChef(new CheeseBurgerRecipe());
new BurgerChef(new ChickenBurgerRecipe());위와 같이 외부에서 어떤 레시피를 사용할지 DI 해준다면 클라이언트(버거 쉐프)의 코드를 수정할 필요가 없습니다. 이때 당연히 각각의 레시피는 BurgerRecipe라는 인터페이스를 구현하고 있어야 합니다!

스프링을 기준으로 보자면, 외부의 대상인 IOC 컨테이너가 빈을 알아서 주입해 주는 것입니다 :)
DI 방법
1. 필드 주입
@Service
public class BurgerService {
@Autowired
private BurgerRecipe burgerRecipe;
}필드 주입 방법은 변수 선언부에 @Autowired 어노테이션을 붙입니다.
이 경우 코드가 간단해진다는 장점이 있지만 Solid 원칙 중 단일 책임 원칙(SRP)을 위반하고, Unit Test가 어렵습니다. 또한 final 키워드를 사용할 수 없어 불변성이 보장되지 않고, 객체가 변할 수 있습니다.
필드 주입을 사용하면 클래스 내에서 의존성 관리의 책임까지 가져야 합니다. 이로 인해 클래스의 책임이 분산되어 코드가 복잡해지고 유지 보수가 어려워집니다.
이때 IOC 컨테이너가 DI를 해주는 것인데.... 왜 클래스가 의존성 관리의 책임까지 진다고 할 수 있을까요??
필드 주입 방식을 사용하면, 클래스는 생성된 이후 언제든지 필드가 변경될 수 있다는 점에 대해 인지하고 있어야 하므로, 이는 암묵적으로 해당 클래스가 필드의 상태 관리 책임을 가지게 됩니다. 즉 클래스는 핵심 비즈니스 로직에 집중하는 것 외에도 필드의 상태를 체크하고 관리하는 부가적인 책임을 가져야 합니다.
또한 필드 주입 방식에서는 객체를 먼저 생성하고, 이후에 필드에 값을 주입하는 과정을 거치기 때문에 final 필드에 값을 주입할 수 없습니다. final의 경우엔 선언과 동시에 초기화하거나, 생성자에서 초기화하는 것만 허용하기 때문입니다.
2. 수정자 주입
@Service
public class BurgerService {
private BurgerRecipe burgerRecipe;
@Autowired
public void setBurgerRecipe(BurgerRecipe burgerRecipe) {
this.burgerRecipe = burgerRecipe;
}
}수정자 주입은 setter라 불리는 필드의 값을 변경하는 수정자 메서드를 통해서 의존관계를 주입하는 방법입니다. 이는 보통 변경 가능성이 있는 의존관계에 주로 사용합니다.
객체의 생명 주기 중에 의존성을 변경할 수 있고, 모든 의존성이 생성시점에 필요하지 않은 경우 선택적으로 일부 의존성만 주입할 수 있다는 장점을 가집니다.
하지만 이 역시 필드 주입과 마찬가지로 클래스가 의존성의 생명 주기를 관리하거나 상태를 체크하는 부가적인 책임을 가질 수 있어 SRP에 위배됩니다. 또한 선택적인 의존성을 사용할 수 있기에 필수적이지 않은 의존성을 주입하지 않고도 객체를 생성할 수 있지만, 이렇게 선택적 의존성이 주입되지 않았을때, 해당 의존성을 사용하는 메서드가 호출되면 NPE가 발생할 수 있습니다.
(또한 public 으로 열어 두어야 하기에 누군가 개발을 하다가 변경할 수도 있음... 이런 문제를 사전에 막는것이 좋음)
(객체 생성 이후에 별도의 setter 메서드를 호출하여 필요한 의존성을 주입합니다.따라서 final 키워드 사용 불가)
3. 생성자 주입
@Service
public class BurgerService {
private BurgerRecipe burgerRecipe;
@Autowired
public BurgerRecipe(BurgerRecipe burgerRecipe) {
this.burgerRecipe = burgerRecipe;
}
}생성자에 @Autowired 어노테이션을 붙여 의존성을 주입받는 방식으로, 가장 권장 되는 주입 방식입니다.
이러한 생성자 주입 방법은 다른 주입 방법과 다르게 객체가 생성되는 시점에 의존성을 생성자 인자로 주입받기에, 필드에 final 키워드를 사용할 수 있어 불변성을 보장할 수 있습니다. 또한 생성자 주입을 사용하면 순환 참조를 컴파일 시점에 확인할 수 있습니다. 생성자 주입 방법의 경우 만약 순환 참조가 발생하면 애플리케이션이 구동되지 않으므로, 문제를 미리 파악하고 해결할 수 있습니다.
(순환참조 : 서로 다른 여러 빈들이 서로를 참조하고 있음 ex) A -> B, B -> A)
(서로 호출을 끊임없이 하다가 StackOverflow가 발생할 수 있음)
생성자 주입 사용시, 클래스 생성과 동시에 의존성이 주입되어야 하에, 생성자 호출 시점에 모든 의존성이 주입되어야 하므로 순환참조가 발생하면 애플리케이션이 시작되지 않습니다. 반면 필드 주입이나 수정자 주입 방식은 객체가 생성 후에 의존성 주입이 이루어지므로 우선 순환참조가 발생해도 애플리케이션 시작 시점엔 문제가 발생하지 않습니다. 하지만 비즈니스 로직 상에 순환참조가 일어난다면, 런타임시점에 이를 알 수 있습니다.
그리고 생성자 주입을 사용시 테스트 코드 작성 또한 용이합니다.
만약 테스트하고자 하는 클래스에 필드 주입이나 수정자 주입으로 빈이 주입되어 있으면, Mockito를 이용해 목킹 후 테스트를 진행해야 합니다. 하지만 생성자 주입의 경우는 단순히 원하는 객체를 생성한 후, 생성자에 넣어주는 방식으로도 진행이 가능합니다.
'SPRING > 영한님 강의 - 스프링 핵심원리 기본편' 카테고리의 다른 글
| 빈 스코프(Singleton, Prototype, 웹 관련), 빈 스코프 활용하여 로그 (0) | 2023.07.11 |
|---|---|
| 스프링 빈 라이프 사이클 알아보기 + 소멸, 생성주기 콜백 (0) | 2023.07.10 |
| 좋은 객체 지향 프로그래밍이란 무엇일까(다형성, SOLID) (0) | 2023.07.08 |


